
SendingDataToCloudNineReview.pdf
Sending Data to CloudNine Review
When you choose CloudNine Review, you have the flexibility to decide how you want to deliver your data to CloudNine. There are two ways to submit your data:
- Discovery Portal: A self-service gateway to upload your data into CloudNine Review. With CloudNine Discovery Portal, you can:
- Upload native (unprocessed) data.
- Upload Production / Processed data with DAT and OPT load files directly to CloudNine Review or send to CloudNine’s Client Service Team.
- Push data from other CloudNine Applications to CloudNine Review.
- Client Services Team: Data may be sent directly to CloudNine’s client services team via FTP or shipment. The client services team can:
- Process raw data, then upload it to CloudNine Review.
- Upload processed data to CloudNine Review.
Native / Raw data
Simply put, raw data is data in its original state (or collected state) that has not undergone any type of processing.
Production / Processed Data
Discovery Data has been processed, either through scanning (paper discovery) or electronic discovery processing. Electronic Discovery processing includes expanding container files (mailstores, compound documents, archive files, etc.) and extracting metadata and text associated with them.
Whether you process the data yourself using a processing application such as CloudNine LAW or receive processed data from a third party, the data is often received in the following manner.
Data Volume (Folder Organization)
Generally, processed data is delivered in Volume folders. Each volume is named uniquely and contains the following sub-folders:
- Images: TIF or PDF files, based on the agreed-upon delivery format.
- Native: Output of corresponding native files. This may be limited to specific file types, such as Excel files or those that cannot be converted to an image format.
- Text: The corresponding OCR or extracted text.
- Data: The load files used to load (import) data into CloudNine Review, as well as any supporting files such as error logs, privilege logs, etc. A DAT load file is used to import metadata. An OPT or LFP load file is used to link images to the records.
CloudNine Review Specifications
CloudNine Review supports the following options.
Image Formats
CloudNine Review supports black-and-white and color images in multiple formats.
- Single-Page TIF / JPG
- Multi-Page TIF
- Multi-Page PDF (Recommended)
OCR Text Protocol
- Multi-Page text files (Recommended)
- Single-Page text files – file name must match the corresponding TIF image.
- Text path in the data load file that points to the relative path to the text file.
Naming Protocol
- Files should be uniquely named with an incremental numbering scheme.
- Single-page Image files are typically named by the unique Page ID.
- Multi-page PDF files are named the unique DocID or BegDoc.
- Native, text, and images files follow the same naming convention.
Load Files
MetaData File: A delimited text file used to create records and populate fields with the metadata for the record. For CloudNine Review, a DAT load file is recommended. The DAT load file is a delimited text file using delimiters not typically used in everyday language. The DAT file must include:
- Header Row of Field Identifiers: Used for mapping data in the load file to fields in the database.
- Fields separated by delimiters:
- A .DAT file using the standard
- Field Qualifier:I (020)
- Text Delimiter:þ (254)
- Newline: ® (174)
- Required Fields for TIF, Text, and Native file loads
- BEGDOC# (DOCID, CONTROL NUMBER, ETC): The unique identifier that is used to link metadata, text, natives, and image files. This field is usually the first field in the load file.
- NativeFile: If native files are included, the relative path to native files.
- TextFile: If text files are included, the relative path to the corresponding text file.
- Parent ID or BegAttach: Maintains family relationships.
- A .DAT file using the standard
- The metadata (DAT or CSV) file should not contain:
- OCR or Extracted Text.
- Message Body.
- Conversation String.
Metadata Example

Image Load File Example
Image Load File: If your data has been converted to an image format, you will need an image load file to link the images to the corresponding metadata record in CloudNine Review. While we can accept other image load file types, we strongly recommend an LFP or OPT load file.
LFP Load File Examples
Single-Page Image Load File
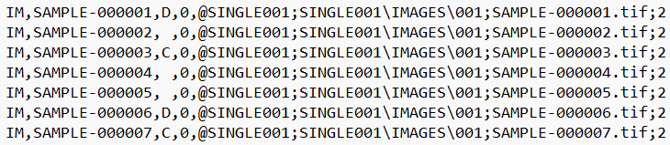
Example of Multi-Page PDF load file
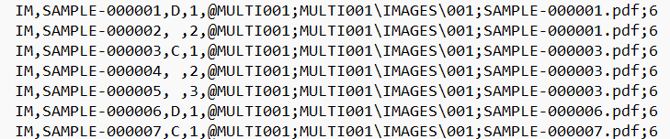
OPT Load File Example
Single-Page OPT Load File
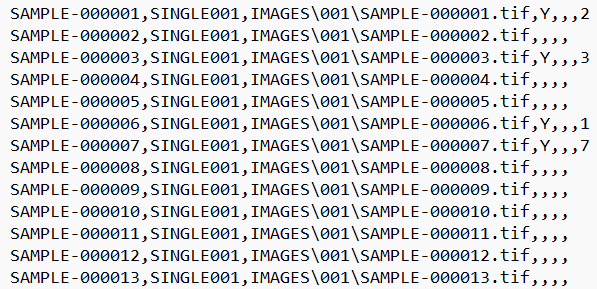
Multi-Page OPT Load File
